Demystifying tables (cells inside; borders outside)
Whenever you stumble upon the table in the text you're reading, you are supposed to intuitively grasp the meaning behind the data presented in this way - the table data structure was created with humans in mind.
If you try to google up "table notation" or "how to read tables" you will find the instructions for how to make your software parse the tables. Humans, on the other hand, should find it self-evident!

for Scientific and Enterprise Applications" - http://www.vldb.org/pvldb/vol13/p3433-burdick.pdf
I might find the table notation self-evident if I consider the contents of the table, however guessing the meaning of the notation from the content sounds like such a displeasure!
Let's formalize the table notation.
Notation: regardless of content
The Cartesian Plane
Any table is 2D, and could be represented on a Cartesian plane.
Any table, no matter how complex, consists of:
- an x-axis with header cells,
- an y-axis with header cells,
- content cells, each corresponding to one and only one (x, y) header pair, and
- categories, non-cells that simply group header cells.
(mirrored for our comfort)
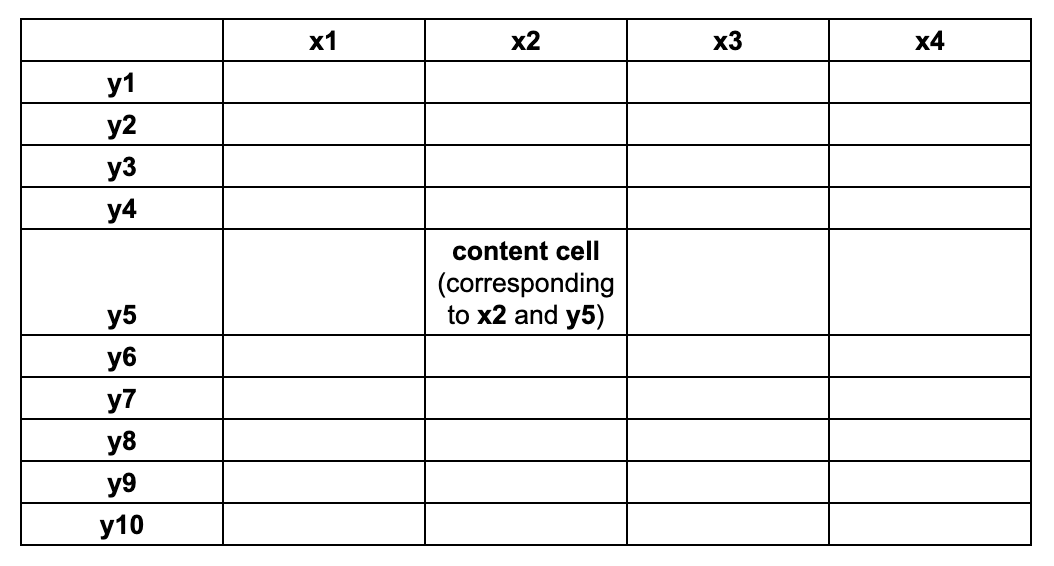
We can convert any table in nature to this simplified structure, let's call this simplified table the normalized table.
Categories
It is frequently the case, that the header cells y1, y2 and y3, for example, belong to the same category of an object, and y4, y5, and y6 belong to the other category.
In the normalized table, we'd to represent this by mentioning the category the header cell belongs to in each header cell separately:
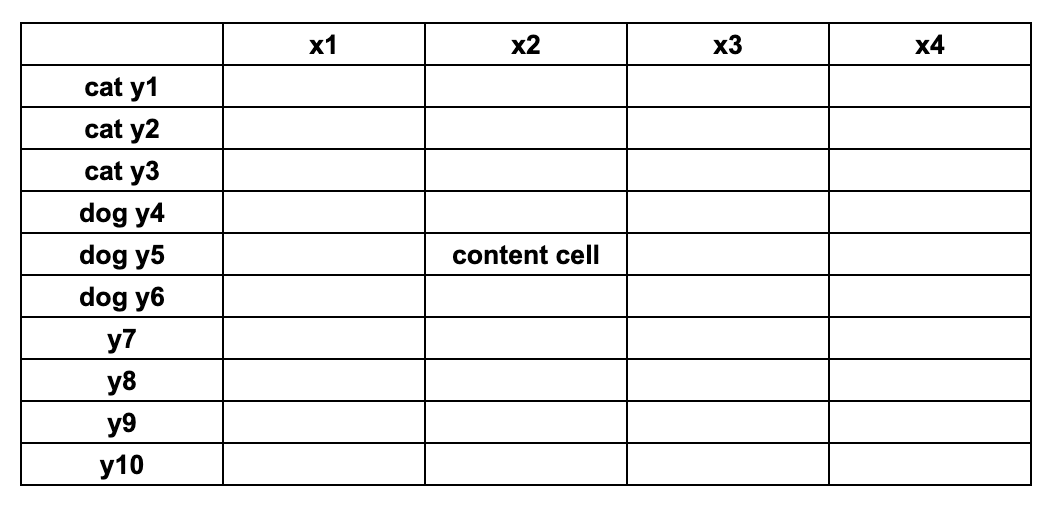
However, this can start looking bulky, and you would frequently see such cascading design:
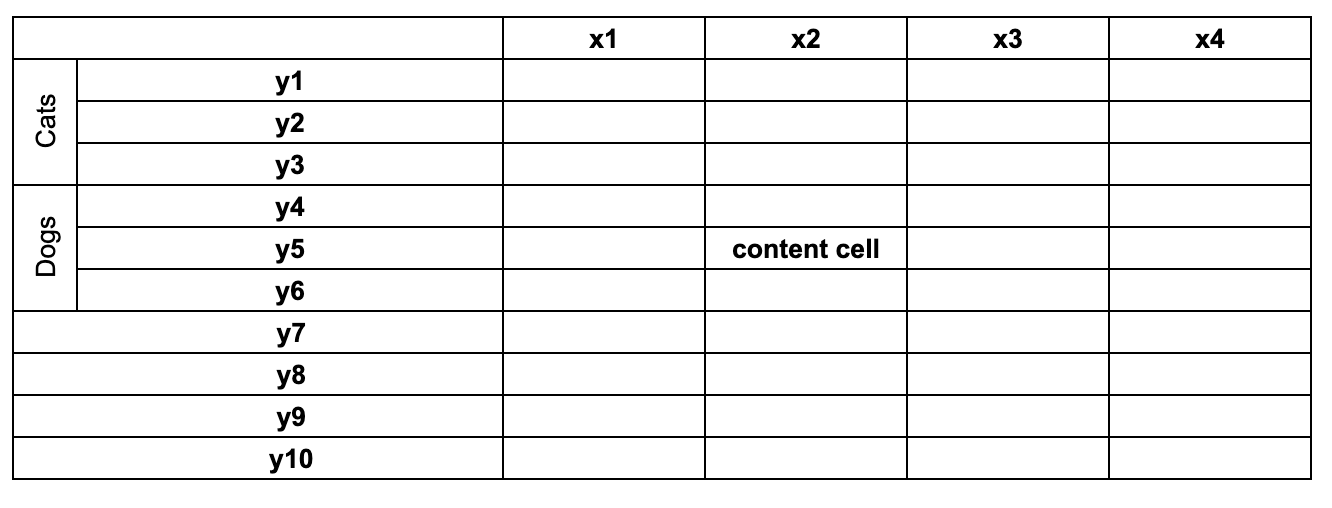
Notice how we still use a strictly 2D data structure. "Cats" and "Dogs" are not table cells - it's simply the syntax sugar that helps us avoid repeating the category in each header cell.
This cascading can grow arbitrarily complex, but it can always be flattened into the 2D structure.
The evil: (0, 0) cell
You may have noticed that our normalized tables never fill the leftmost topmost cell.
This can't be a header cell, no content cells would be able to be targeted by it.
In real tables, it's frequently filled, and this is where we're reduced to needing to look at the meaning of the words in our table cells in order to parse the table notation.
The leftmost topmost cell is, either or:
- a category for all the x-axis header cells
- a category for all the y-axis header cells.
You must read the content of the header cells to determine which it is in this particular table.
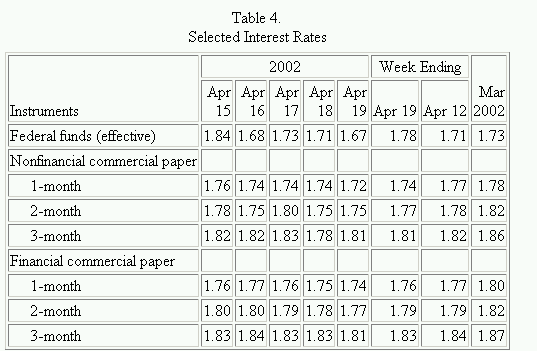
In our "table with complex cascading", for example, the (0, 0) cell is filled with the word "Instruments". Looking at the x-axis header cells, we see "Instruments: 2002, Apr 15". Looking at our y-axis header cells, we see "Instruments: Federal funds (effective)".
The latter makes more sense (as much as something this bureaucratic can), and we assume that this fake (0, 0) cell is in fact a category for the entire y-axis header column.
Notation: considering content
As you saw with the evil (0, 0) cell, at some point we have to start looking at the meaning behind the text in our cells.
Take a look at the following table, ironically taken from the "Writing Clear Science" blog.

Looking purely at the form of the table, one would guess that these are the x-axis and y-axis headers:
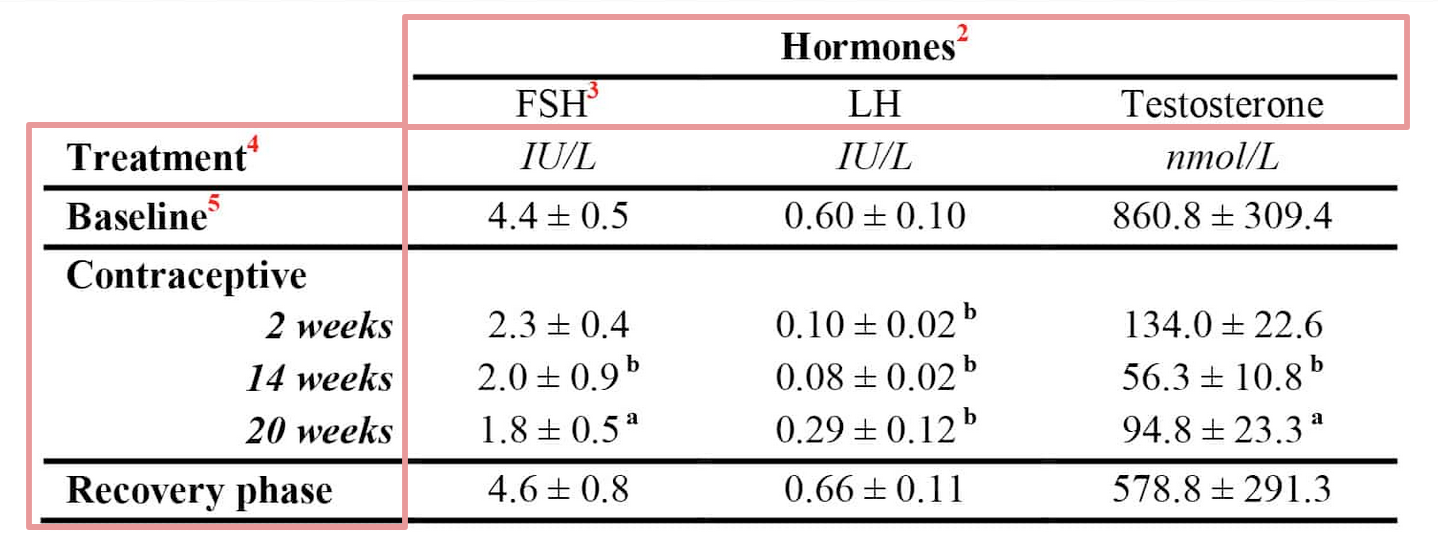
However, this is not the case. "Treatment" is in fact the evil (0, 0) cell, and "IU/L" is not a content cell - it's a part of the header cell.
Here is how we would normalize this table:

If your table is already in the normalized state, as shown above, you wouldn't need to read its contents to understand its structure, and I'd argue that's how notation should be.
Reading the table
In a perfect world, we wouldn't have to read through the text in the table to parse its structure. However, even if the structure of our table is perfect, some guessing is still necessary to understand the contents of the table!
What's left ambiguous is the verb that connects the (x1, y1) header cell tuple to the content cell. To be able to read the table as if it's a proper straightforward text, we need some sentence template "x1 verb y1".
Some authors helpfully include such a "x1 verb y1" sentence template in the table caption. More frequently, we are to glean the necessary sentence structure from the surrounding context, and I found it incredibly helpful be conscious of this necessity and of this process.